vLLM 완전 정복 — 파라미터부터 최적화까지, 로컬 LLM 서빙의 모든 것
로컬 GPU에서 LLM을 서빙하려는 엔지니어들이 가장 먼저 마주치는 도구가 vLLM이다. 설치부터 서버 기동까지는 10분도 안 걸린다. 문제는 그다음이다. --gpu-memory-utilization을 어떻게 설정해야 하는지, --tensor-parallel-size와 --enable-expert-parallel의 차이는 무엇인지, FP8 양자화를 쓰면 실제로 얼마나 빨라지는지 — 공식 문서만으로는 답이 나오지 않는 질문들이 쌓인다. 이 글은 그 질문들에 직접 답하는 실전 가이드다.
vLLM이 핫한 이유: PagedAttention과 Continuous Batching
vLLM의 핵심 논문은 2023년 SOSP에서 발표된 Kwon 등의 연구다1. 당시 LLM 서빙 시스템들이 공통으로 겪던 문제는 GPU 메모리 낭비였다. 트랜스포머의 어텐션 메커니즘은 각 토큰에 대해 Key와 Value 벡터를 생성하고 저장하는데, 이 KV 캐시가 메모리를 연속된 블록으로 점령한다. 문제는 요청마다 생성될 토큰 수를 미리 알 수 없기 때문에, 기존 시스템은 최악의 경우를 가정하고 메모리를 예약(reservation)해둬야 했다. 그 결과 실제 KV 캐시 메모리의 60–80%가 낭비됐다.
PagedAttention은 이 문제를 OS의 가상 메모리 페이징 방식으로 해결했다1. 운영체제가 물리 메모리를 고정 크기 페이지로 나눠서 프로세스에 비연속적으로 할당하듯, vLLM은 KV 캐시를 고정 크기 블록(기본값 16토큰)으로 나눠서 비연속 메모리에 저장한다. 요청이 실제로 토큰을 생성할 때마다 블록을 동적으로 할당하니 낭비가 사라졌다. 이로써 vLLM은 기존 시스템 대비 처리량을 최대 24배까지 향상시켰다고 논문은 보고했다.

Continuous Batching은 또 다른 혁신이었다. 기존 static batching에서는 배치 안의 모든 요청이 끝날 때까지 새 요청을 받지 않았다. 한 요청이 1000토큰을 생성하는 동안 100토큰 요청들이 줄을 서야 했다. Continuous Batching은 iteration마다 완료된 요청을 배치에서 빼고 새 요청을 즉시 집어넣는다. GPU가 항상 꽉 찬 배치를 처리하므로 처리량이 극적으로 올라갔다2. Anyscale의 연구에 따르면 Continuous Batching은 static batching 대비 p50 레이턴시를 낮추면서 동시에 23배 처리량 향상을 달성했다.
파라미터 완전 해부

모델 로딩: 기본부터 잡아야 한다
vllm serve <model> 명령의 가장 기본적인 파라미터들부터 정리하면 아래와 같다.
| 파라미터 | 기본값 | 설명 |
|---|---|---|
--model | — | HuggingFace 모델 이름 또는 로컬 경로 |
--tokenizer | model과 동일 | 별도 토크나이저가 필요할 때 지정 |
--tokenizer-mode | auto | auto/hf/mistral/deepseek_v32 |
--dtype | auto | auto/bfloat16/float16/float32 |
--quantization | None | awq/gptq/fp8/bitsandbytes/gguf 등 |
--max-model-len | 모델 config 자동 | 최대 컨텍스트 길이 (입력+출력) |
--trust-remote-code | False | 커스텀 모델 코드 실행 허용 |
--load-format | auto | auto/safetensors/gguf/bitsandbytes 등 |
--dtype auto는 모델의 torch_dtype 기준으로 자동 결정되는데, BF16 모델에 --dtype float16을 강제하면 정밀도 손실이 생긴다. 특별한 이유가 없다면 auto를 그대로 쓰는 것이 맞다.
--trust-remote-code는 Qwen3, InternLM 계열 모델에서 필수다. HuggingFace 리포에 올라온 커스텀 Python 파일을 실행하는 것이므로, 신뢰하는 공식 리포 모델에만 사용해야 한다.
--max-model-len은 단순히 “얼마나 긴 문서를 처리하느냐”의 문제가 아니다. 이 값은 KV 캐시 메모리 총량에 직접 비례한다. Qwen3-235B처럼 무거운 모델을 돌릴 때 이 값을 크게 설정하면 KV 캐시가 모델 가중치보다 더 많은 메모리를 먹을 수 있다. 아래 메모리 계산 섹션에서 구체적으로 다룬다.
GPU 메모리와 병렬화: 가장 중요한 설정들
병렬화 전략: TP vs PP vs EP
세 파라미터의 역할을 명확히 이해하는 것이 vLLM 설정의 핵심이다.
--tensor-parallel-size(줄여서 -tp)는 모델의 가중치 행렬을 여러 GPU에 나눠서 계산한다. 같은 노드 내 NVLink로 연결된 GPU들 사이에서 all-reduce 통신이 빠르게 이뤄지기 때문에 레이턴시가 낮다. 대부분의 상황에서 첫 번째로 고려할 옵션이다.
--pipeline-parallel-size(줄여서 -pp)는 모델의 레이어를 GPU에 순서대로 배분한다. A라는 GPU가 앞쪽 레이어를 처리하고, B라는 GPU가 뒷쪽 레이어를 처리한다. 이 경우 “파이프라인 버블”이 발생해 GPU 활용률이 TP보다 낮아진다. 노드 간(inter-node) 연결처럼 대역폭이 좁은 환경이거나, TP만으로 모델이 안 들어갈 때 보조적으로 쓰는 옵션이다.
--enable-expert-parallel(줄여서 -ep)는 MoE(Mixture of Experts) 모델 전용이다. Qwen3-235B-A22B, DeepSeek V3, Llama 4 Maverick처럼 MoE 아키텍처를 쓰는 모델에서 TP 대신 EP를 활성화하면 expert 연산 부하를 GPU들 사이에 균등하게 분산할 수 있다. TP를 MoE에 적용하면 각 expert 가중치도 잘게 나뉘어서 오히려 비효율적인 경우가 많다.
H200 두 장에서 Qwen3-235B-A22B를 돌린다면 결론은 간단하다: -tp 2 --enable-expert-parallel.
| 전략 | 적합한 상황 | 주의점 |
|---|---|---|
--tensor-parallel-size N | 같은 노드 내 NVLink GPU | NVLink 대역폭 필요, 레이턴시 최소 |
--pipeline-parallel-size N | 노드 간 분산, TP 한계 초과 시 | 파이프라인 버블로 효율 저하 |
--enable-expert-parallel | MoE 모델 전용 | TP와 병행 설정 가능 (-tp 2 -ep) |
메모리 삼각관계: gpu-memory-utilization, max-model-len, max-num-seqs
이 세 파라미터는 서로 연동되어 움직인다. 하나를 바꾸면 나머지 두 개의 허용 범위가 달라진다.
--gpu-memory-utilization(기본값 0.9)은 GPU 메모리 중 vLLM 엔진이 사용할 비율이다. H200(141GB)에서 0.9를 설정하면 약 127GB를 모델 가중치 + KV 캐시에 사용한다. 이 값을 높이면 KV 캐시 공간이 넓어지므로 더 많은 동시 요청을 처리할 수 있지만, 나머지 GPU 메모리(약 14GB)가 줄어드니 시스템 스택이나 PyTorch 내부 버퍼가 쓸 여유가 없어진다.
--max-model-len은 최대 컨텍스트 길이다. 이 값이 크면 한 요청이 KV 캐시를 많이 쓴다. 반대로 이 값이 작으면 같은 메모리로 더 많은 요청을 동시에 처리할 수 있다.
--max-num-seqs(기본값 256)는 한 번에 처리할 최대 시퀀스 수다. 이 값이 크면 동시 요청 수가 늘어나므로 KV 캐시 총 소비량이 늘어난다.
세 파라미터의 관계를 정리하면:
KV 캐시 가용 메모리 = (GPU 메모리 × gpu-memory-utilization) - 모델 가중치 메모리
최대 동시 시퀀스 × KV cache/시퀀스 ≤ KV 캐시 가용 메모리
여기서 KV cache/시퀀스 ∝ max-model-lenOOM이 발생할 때 먼저 --max-model-len을 줄이고, 그다음 --max-num-seqs를 줄이는 순서로 접근하는 것이 합리적이다.
양자화 선택: fp8, awq, gptq, bitsandbytes의 실전 차이
--quantization 옵션별 특성을 실전 관점에서 정리했다.
| 방식 | 정밀도 타입 | 요구 하드웨어 | 속도 | 메모리 절약 | 비고 |
|---|---|---|---|---|---|
fp8 | W8A8 (FP8) | H100, H200, Ada+ | ★★★★★ | ~50% | 가장 빠름. 공식 FP8 체크포인트 활용 |
awq | W4A16 | 모든 NVIDIA GPU | ★★★★☆ | ~75% | Marlin 커널 자동 적용. --dtype half 권장 |
gptq | W4A16 또는 W8A16 | 모든 NVIDIA GPU | ★★★★☆ | ~75% | gptq_marlin 커널 자동 사용 |
bitsandbytes | NF4, Int8 | CPU 포함 | ★★☆☆☆ | ~75%+ | 메모리 절약 극대화. 속도는 가장 느림 |
gguf | 다양 | 모든 GPU | ★★★☆☆ | 가변 | --load-format gguf 필수. MoE 지원(v0.8+) |
FP8은 H100/H200이 있다면 가장 강력한 선택이다. 모델 가중치와 활성값 모두 FP8로 처리하므로 메모리와 연산 양쪽에서 이점을 얻는다. Qwen3-235B-A22B처럼 공식 FP8 체크포인트(Qwen3-235B-A22B-FP8)가 제공되는 경우 동적 FP8 양자화보다 품질이 더 안정적이다.
AWQ는 가중치 양자화 시 활성값 분포를 고려해 중요한 채널을 보호하는 방식이라 GPTQ보다 품질 저하가 적은 편이다3. H100이 없는 환경에서 4-bit 양자화를 써야 한다면 AWQ가 첫 번째 선택지다.
bitsandbytes는 NF4나 Int8 방식으로 소비 메모리를 극한까지 줄이고 싶을 때 쓴다. 단, Marlin 커널을 지원하지 않아서 속도 면에서 AWQ나 GPTQ보다 느리다. 메모리가 매우 부족한 상황의 차선책으로 보는 게 맞다.
FP8 KV 캐시의 효과
--kv-cache-dtype fp8는 모델 가중치 양자화와 별개로 KV 캐시만 FP8로 저장하는 옵션이다. 효과는 두 가지다.
첫째, KV 캐시 메모리가 절반으로 줄어든다. BF16이 16-bit이고 FP8이 8-bit이니 당연하다. 이로 인해 같은 메모리에서 더 많은 동시 시퀀스를 처리하거나, 더 긴 컨텍스트를 다룰 수 있다.
둘째, H100/H200에서 FlashInfer 백엔드가 FP8 GEMM 하드웨어 가속을 활용한다. 품질 손실은 일반적으로 무시 가능한 수준이라고 알려져 있다. CUDA 11.8 이상과 H100/H200/Ada Lovelace 계열 GPU가 필요하다는 제약이 있다.
# FP8 가중치 + FP8 KV 캐시 조합 (H200 최적 설정)
vllm serve Qwen/Qwen3-235B-A22B-FP8 \
--quantization fp8 \
--kv-cache-dtype fp8 \
--dtype bfloat16스케줄링: Chunked Prefill과 배치 크기 튜닝
--max-num-batched-tokens는 vLLM V1에서 Chunked Prefill의 핵심 파라미터다. 한 스케줄링 스텝에서 처리할 최대 토큰 수를 설정한다.
이 값이 작으면(예: 2048) decode 요청이 prefill보다 먼저 처리될 기회가 많아져 토큰 간 레이턴시(ITL, Inter-Token Latency)가 줄어든다. 사람이 실시간으로 스트리밍을 보는 상황이라면 이 값을 낮추는 게 유리하다.
이 값이 크면(예: 32768 이상) prefill 청크를 한 번에 많이 처리하므로 TTFT(Time To First Token)가 개선되고 전체 처리량이 올라간다. 오프라인 배치 처리라면 이 값을 크게 잡아야 한다.
V1에서는 --enable-chunked-prefill이 기본 활성화되어 있으므로 --max-num-batched-tokens만 상황에 맞게 조정하면 된다.
투기적 디코딩(Speculative Decoding): 실전 사용법
--speculative-config는 JSON 형태로 투기적 디코딩을 설정한다. 원리는 작은 draft 모델이 여러 토큰을 예측하고, 큰 메인 모델이 한 번에 검증하는 방식이다. 검증이 한 번에 이뤄지므로 decode 레이턴시를 줄일 수 있다.
방법 1: N-gram
입력 프롬프트의 n-gram을 재사용해 토큰을 예측한다. 별도 모델이 필요 없으므로 GPU 메모리를 추가로 쓰지 않는다. 코드나 반복적 패턴이 많은 문서에서 효과적이다.
--speculative-config '{"method": "ngram", "num_speculative_tokens": 5, "prompt_lookup_min": 3, "prompt_lookup_max": 10}'방법 2: Draft 모델
메인 모델과 같은 토크나이저를 쓰는 작은 모델을 draft로 쓴다. 같은 모델 패밀리의 소형 버전을 활용하면 accept rate가 높아진다.
--speculative-config '{"model": "meta-llama/Llama-3.1-8B-Instruct", "num_speculative_tokens": 5}'방법 3: EAGLE3
특수 훈련된 draft 헤드를 활용하는 방식으로, 현재 투기적 디코딩 중 가장 높은 accept rate를 보인다4. V1에서 prefix caching, chunked prefill과 함께 동작한다.
--speculative-config '{
"method": "eagle3",
"model": "yuhuili/EAGLE3-LLaMA3.1-Instruct-8B",
"num_speculative_tokens": 3,
"draft_tensor_parallel_size": 1
}'num_speculative_tokens는 3–5가 일반적으로 최적이다. 너무 크면 accept rate가 낮아져 오히려 속도가 떨어진다. MoE 모델에는 투기적 디코딩이 잘 맞지 않는 편인데, 활성 파라미터가 적은 MoE 모델의 분포 특성이 draft 모델과 맞지 않아서다.
버전별 진화: v0.4에서 v0.8까지
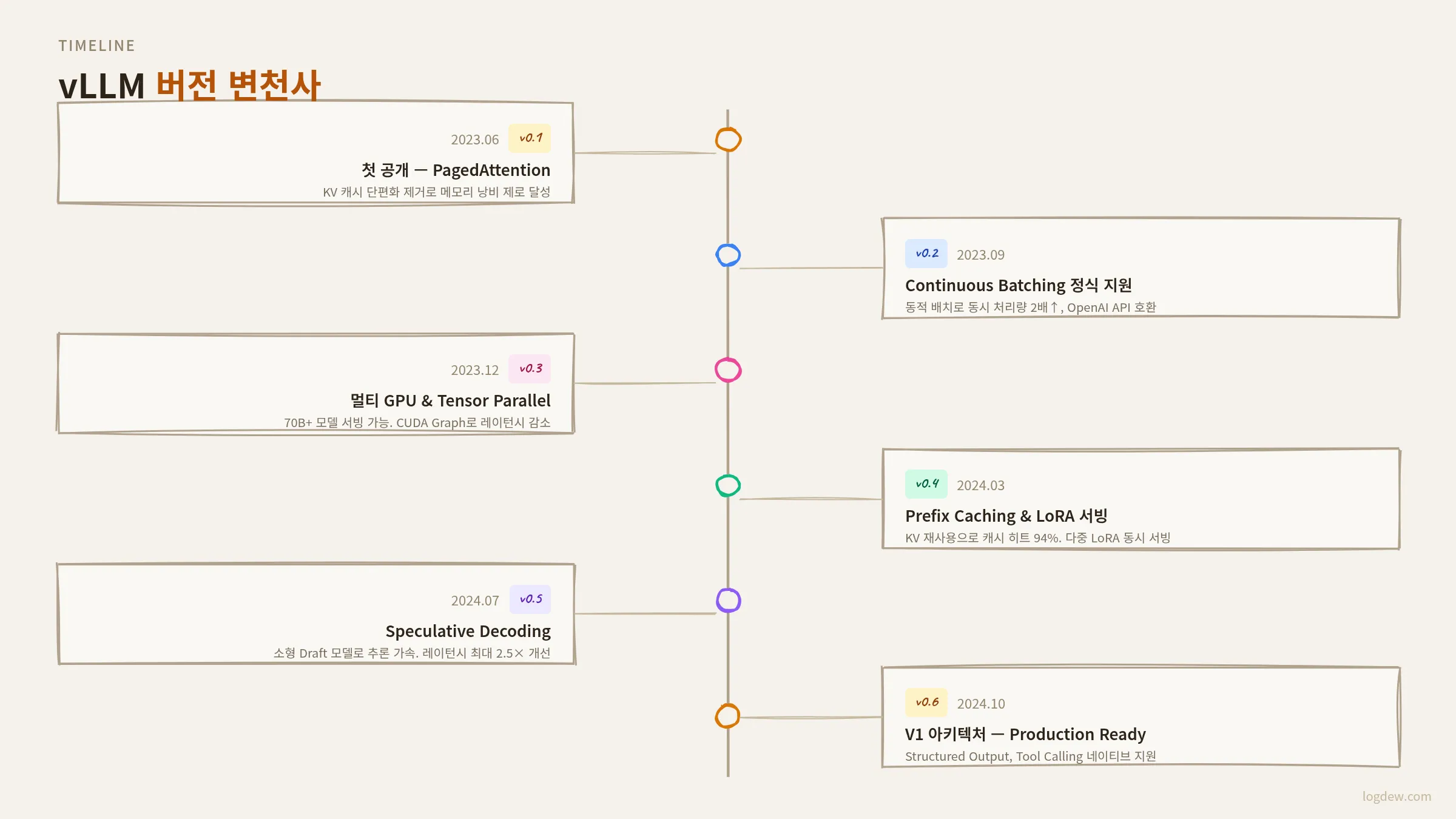
버전별 핵심 변화
v0.4.x (2023 하반기) — PagedAttention v1, Continuous Batching, AWQ/GPTQ 양자화
v0.5.x (2024 상반기) — Chunked Prefill (옵션), Prefix Caching (옵션), Speculative Decoding 초기 지원
v0.6.x (2024 하반기) — v0.5.3 대비 1.8–2.7배 처리량 향상, FP8 KV Cache, bitsandbytes FP4 지원
v0.7.x (2025년 1월) — V1 엔진 베타, DeepSeek V3/R1 지원, FlashAttention 3
v0.8.x (2025년 2월) — V1 엔진 기본값, Expert Parallelism, Gemma 3, Blackwell 지원
v0.9+ (2025 중반 이후) — V0 백엔드 완전 제거 예정특히 v0.6.0의 성능 향상은 단순한 버그픽스가 아니었다5. Multi-step 스케줄링과 비동기 출력 처리(async output processor)를 통해 GPU 연산과 CPU의 출력 처리를 겹치게 만들면서 12% 추가 처리량 향상이 이뤄졌다. Chunked Prefill과 Prefix Caching을 동시에 쓸 수 있게 된 것도 이 버전부터였다.
V0 → V1 엔진 전환이 왜 중요한가
V0 엔진의 가장 큰 문제는 아키텍처의 동기성이었다. 스케줄러가 한 iteration에서 prefill 또는 decode 중 하나만 처리하다 보니 리소스 활용에 한계가 있었다.
V1은 이 구조를 완전히 재설계했다6. ZMQ 기반 비동기 API 서버로 전환하고, 스케줄러를 통합해서 prefill과 decode를 하나의 흐름으로 처리한다. torch.compile이 완전히 통합되어 추가 최적화가 가능해졌고, Chunked Prefill과 Prefix Caching이 기본값으로 활성화됐다.
| 항목 | V0 | V1 (v0.8+ 기본값) |
|---|---|---|
| 스케줄러 | prefill/decode 분리 | 통합 스케줄러 |
| Chunked Prefill | 옵션 (비활성화 기본) | 기본 활성화 |
| Prefix Caching | 옵션 (비활성화 기본) | 기본 활성화 |
| Preemption 기본값 | SWAP | RECOMPUTE |
| torch.compile | 부분 지원 | 완전 통합 |
| 아키텍처 | 동기 | ZMQ 기반 비동기 |
V0으로 돌아가려면 환경변수 VLLM_USE_V1=0을 설정한다. V1이 지원하지 않는 기능을 쓸 때 자동으로 V0 폴백이 이뤄지기도 한다.
자주 만나는 에러와 해결법
OOM: 단계별 접근법
OOM이 발생했을 때 순서대로 시도할 방법들이다.
--max-model-len축소: KV 캐시 요구량 직접 감소. 가장 효과가 크다.--max-num-seqs감소: 동시 시퀀스 수를 줄여 KV 캐시 총량 감소.--kv-cache-dtype fp8추가: KV 캐시 메모리 50% 절약.--tensor-parallel-size증가: GPU당 모델 메모리 감소로 KV 캐시 공간 확보.--quantization fp8또는awq적용: 모델 가중치 자체를 줄임.
--gpu-memory-utilization을 올리는 것은 마지막 수단이다. 0.95 이상으로 올리면 PyTorch 내부 버퍼나 CUDA 그래프 캡처 시 OOM이 발생할 수 있다.
CUDA 에러 해결
CUDA illegal memory access (MoE 모델에서 자주 발생):
H20 GPU에서 MoE FP8 관련 불법 메모리 접근 문제가 v0.8 이전 버전에서 보고됐다. v0.8.0 이상으로 업그레이드하면 해결된다.
CUDA graph capture failed:
--enforce-eager 플래그를 추가해 CUDA 그래프를 비활성화한다. 디버깅할 때도 유용하다.
FP16 overflow (DeepSeek V2 등):
--dtype bfloat16으로 전환한다. FP16의 표현 범위(최대 65504)로는 LLM 가중치의 큰 값들이 오버플로우될 수 있다.
모델 로딩 실패
KeyError: 'qwen3_moe':
transformers 버전이 낮아서 발생한다. pip install transformers>=4.51.0으로 해결한다.
GGUF 로딩 실패:
--load-format gguf와 --quantization gguf를 함께 지정해야 한다.
Qwen3/MoE 계열 특이사항
Qwen3-235B-A22B는 vllm>=0.8.5와 transformers>=4.51.0이 필수다. Qwen3의 thinking mode를 쓸 때는 greedy decoding(temperature=0)을 피해야 한다. temperature가 0이면 무한 반복 생성이 발생하는 알려진 문제가 있다. temperature >= 0.6을 유지하는 것이 권장된다.
Tesla V100, A40, RTX 계열 등 일부 GPU에서 MoE 모델을 돌릴 때 FusedMoE JSON config not found 에러가 나올 수 있다. 해당 GPU 아키텍처에 대한 MoE 커널 튜닝 설정이 없어서다. --enforce-eager로 우회하거나, VLLM_FUSED_MOE_CHUNK_SIZE 환경변수를 조정한다.
실전 디버깅 플로우
# 1단계: eager 모드 + V0 엔진으로 기본 동작 확인
VLLM_USE_V1=0 vllm serve <model> \
--enforce-eager \
--max-model-len 4096 \
--trust-remote-code
# 2단계: 문제가 없으면 V1으로 전환
vllm serve <model> \
--enforce-eager \
--max-model-len 4096 \
--trust-remote-code
# 3단계: CUDA 그래프 활성화 (eager 제거)
vllm serve <model> \
--max-model-len 4096 \
--trust-remote-code
# 4단계: 점진적으로 max-model-len 늘리고 파라미터 추가실전 최적화: Qwen3-235B를 H200x2에서 돌리기
KV 캐시 메모리 계산법
실제로 얼마나 많은 메모리가 KV 캐시에 필요한지 계산하는 공식이다.
KV 캐시 메모리 ≈ 2 × num_layers × num_kv_heads × head_dim × max_model_len × 시퀀스 수 × element_size
Qwen3-235B-A22B (FP8 KV, TP=2):
- num_layers = 94
- num_kv_heads = 4 (GQA, TP=2이면 GPU당 2개)
- head_dim = 128
- element_size: FP8 = 1 byte
max_model_len=32768, 시퀀스 1개:
= 2 × 94 × 2 × 128 × 32768 × 1 × 1 byte
≈ 1.6 GB / 시퀀스
BF16이면 2배 → 3.2 GB / 시퀀스실용적 가이드로 정리하면:
| max-model-len | KV cache / 시퀀스 (FP8) | max-num-seqs 권장 |
|---|---|---|
| 8,192 | ~400 MB | 32–64 |
| 32,768 | ~1.6 GB | 16–32 |
| 131,072 | ~6.4 GB | 4–8 |
FP8 vs BF16 트레이드오프
H200에서 235B 모델을 BF16으로 로딩하면 235B × 2 bytes ≈ 470 GB가 필요하다. H200 두 장의 총 VRAM은 282GB다. 즉, BF16 전체 가중치는 아예 들어가지 않는다. FP8 체크포인트는 235B × 1 byte ≈ 235 GB로, H200x2에 들어갈 수 있다. 여기에 FP8 KV 캐시까지 쓰면 모델 외 메모리는 약 40–50GB가 남아 KV 캐시로 사용된다.
| 항목 | FP8 (H200) | BF16 |
|---|---|---|
| 모델 메모리 (235B) | ~235 GB | ~470 GB (H200x2 초과) |
| 계산 속도 | 최대 2배 빠름 | 기준 |
| 정밀도 | 약간 손실 (공식 ckpt는 검증됨) | 완전한 정밀도 |
| KV 캐시 추가 절약 | --kv-cache-dtype fp8 가능 | 기준 |
| 권장 GPU | H100, H200, Ada+ | 모든 GPU |
처리량 vs 레이턴시 튜닝
목적에 따라 설정을 달리해야 한다.
| 목적 | max-num-seqs | max-num-batched-tokens | gpu-memory-utilization |
|---|---|---|---|
| 최고 처리량 | 256+ | 32768+ | 0.95 |
| 일반 균형 | 64–128 | 8192–16384 | 0.90 |
| 최저 레이턴시 | 8–16 | 2048–4096 | 0.80–0.85 |
| 안정성 우선 | 32 | 8192 | 0.85 |
Prefix Caching 활용법
V1에서는 기본 활성화되어 있으므로 별도 설정이 필요 없다. 효과를 극대화하려면 시스템 프롬프트를 항상 앞에 배치해야 한다. 긴 문서 Q&A처럼 동일한 컨텍스트로 여러 질문을 처리하는 패턴에서 TTFT를 크게 줄일 수 있다.
# Python API에서 prefix caching 활용
llm = LLM(model="...", enable_prefix_caching=True)
# 동일한 시스템 프롬프트를 가진 요청들은 KV 캐시를 자동 재사용환경변수 치트시트
# V1/V0 엔진 선택
VLLM_USE_V1=1 # V1 강제 (v0.8+에서 기본)
VLLM_USE_V1=0 # V0 강제 (디버깅/호환성)
# Attention 백엔드 수동 지정
VLLM_ATTENTION_BACKEND=FLASH_ATTN # Flash Attention
VLLM_ATTENTION_BACKEND=FLASHINFER # FlashInfer
VLLM_ATTENTION_BACKEND=DUAL_CHUNK_FLASH_ATTN # Qwen3 긴 컨텍스트용
# MoE 관련
VLLM_FUSED_MOE_CHUNK_SIZE=32768 # MoE 청크 크기 조정
# 기타
CUDA_VISIBLE_DEVICES=0,1 # 사용할 GPU 지정 (0번, 1번만)
VLLM_MEDIA_LOADING_THREAD_COUNT=8 # 멀티모달 미디어 로딩 스레드 수실전 명령어 모음
기본 서버 시작
vllm serve Qwen/Qwen3-8B-Instruct \
--dtype auto \
--gpu-memory-utilization 0.90 \
--max-model-len 32768 \
--host 0.0.0.0 \
--port 8000 \
--trust-remote-codeMoE 대형 모델: Qwen3-235B on H200x2
vllm serve Qwen/Qwen3-235B-A22B-FP8 \
--tensor-parallel-size 2 \
--enable-expert-parallel \
--dtype bfloat16 \
--kv-cache-dtype fp8 \
--gpu-memory-utilization 0.90 \
--max-model-len 32768 \
--max-num-seqs 32 \
--max-num-batched-tokens 16384 \
--enable-chunked-prefill \
--enable-reasoning \
--reasoning-parser deepseek_r1 \
--trust-remote-code \
--host 0.0.0.0 \
--port 8000고성능 설정: Prefix Cache + Speculative Decoding
vllm serve meta-llama/Llama-3.1-70B-Instruct \
--tensor-parallel-size 4 \
--enable-prefix-caching \
--enable-chunked-prefill \
--max-num-batched-tokens 16384 \
--speculative-config '{"method": "ngram", "num_speculative_tokens": 4, "prompt_lookup_min": 3}' \
--kv-cache-dtype fp8 \
--gpu-memory-utilization 0.92EAGLE3 투기적 디코딩
vllm serve meta-llama/Llama-3.1-70B-Instruct \
--tensor-parallel-size 4 \
--speculative-config '{
"method": "eagle3",
"model": "yuhuili/EAGLE3-LLaMA3.1-Instruct-8B",
"num_speculative_tokens": 3,
"draft_tensor_parallel_size": 1
}' \
--kv-cache-dtype fp8Qwen3 YaRN 장문 컨텍스트 확장 (131K)
vllm serve Qwen/Qwen3-235B-A22B-FP8 \
--tensor-parallel-size 2 \
--enable-expert-parallel \
--max-model-len 131072 \
--rope-scaling '{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":32768}' \
--gpu-memory-utilization 0.85 \
--kv-cache-dtype fp8 \
--max-num-seqs 4 \
--trust-remote-code디버깅용 최소 설정
VLLM_USE_V1=0 vllm serve <model> \
--enforce-eager \
--trust-remote-code \
--max-model-len 4096 \
--max-num-seqs 4 \
--gpu-memory-utilization 0.80vLLM의 파라미터 체계는 처음에는 복잡해 보이지만, PagedAttention과 Continuous Batching이라는 두 가지 핵심 아이디어를 이해하고 나면 각 파라미터가 어떤 트레이드오프를 제어하는지 자연스럽게 보이기 시작한다. 메모리, 레이턴시, 처리량 사이의 균형을 어디에 맞출 것인가 — 그 판단이 vLLM 설정의 본질이다. H200 두 장으로 235B 모델을 돌리는 것이 이제 실전에서 현실적인 선택지가 됐다는 사실 자체가, 이 프로젝트가 2년 만에 이뤄낸 변화를 보여준다.
Footnotes
-
Kwon, W., Li, Z., Zhuang, S., Sheng, Y., Zheng, L., Yu, C. H., Gonzalez, J. E., Zhang, H., & Stoica, I. (2023). “Efficient Memory Management for Large Language Model Serving with PagedAttention.” Proceedings of the 29th Symposium on Operating Systems Principles (SOSP ‘23). ACM. doi:10.1145/3600006.3613165 ↩ ↩2
-
Luo, C., & Stoica, I. (2023). “How Continuous Batching Enables 23x Throughput in LLM Inference while Reducing p50 Latency.” Anyscale Blog. ↩
-
Lin, J., Tang, J., Tang, H., Yang, S., Dang, X., & Han, S. (2023). “AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration.” arXiv:2306.00978. ↩
-
Zhang, Y., et al. (2025). “EAGLE-3: Scaling up Inference Acceleration of Large Language Models via Training-Time Test.” vLLM Blog, December 13, 2025. ↩
-
vLLM Team. (2024). “vLLM v0.6.0: 2.7x Throughput Improvement and 5x Latency Reduction.” vLLM Blog, September 5, 2024. ↩
-
vLLM Team. (2025). “vLLM V1: A Major Upgrade to vLLM’s Core Architecture.” vLLM Blog, January 27, 2025. ↩
댓글